Python pandas 删除指定行/列数据 |
您所在的位置:网站首页 › pandas 删除行 条件 › Python pandas 删除指定行/列数据 |
Python pandas 删除指定行/列数据
|
目录
1.滤除缺失数据dropna()1)滤除含有NaN值的所有行2)滤除含有NaN值的所有列3)滤除元素都是NaN值的行4)滤除元素都是NaN值的列5)滤除指定列中含有缺失的行
2.删除重复值 drop_duplicates()3.根据指定条件删除行列drop()
1.滤除缺失数据dropna()
import pandas as pd
import numpy as np
df=pd.DataFrame({"record":[np.nan,"亚健康|潘光|45岁","疾病|张思",np.nan],"date":[np.nan,20210102,20210103,20210104]},index=["one","two","three","four"])
语法:drop_duplicates(subset,keep,inplace),其中参数 keep:{‘first’,‘last’,False},默认’first’ first:保留第一次出现的重复项,删除第二次及之后出现的重复项。 last:保留最后一次出现的重复项,删除之前出现的重复项。 "false":删除所有重复项。 1)keep=“first” df.drop_duplicates(keep="first")
2)keep=“last” df.drop_duplicates(keep="last")
3)keep=False df.drop_duplicates(keep=False)
2).删除指定行 df.drop([0],axis=0)
|
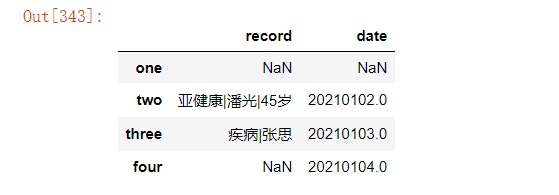


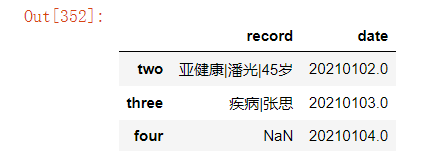
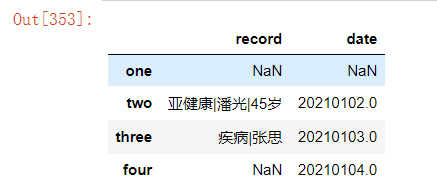
 以上如果需要在原数据上直接做更改,需设置参数inplace=True
以上如果需要在原数据上直接做更改,需设置参数inplace=True
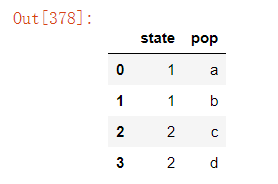
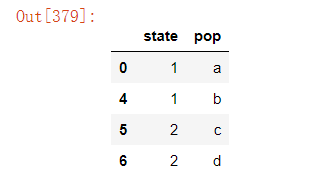
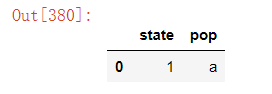 4)删除指定列中重复项对应的行
4)删除指定列中重复项对应的行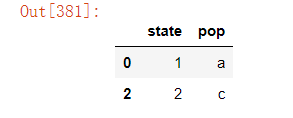 以上如果需要在原数据上直接做更改,需设置参数inplace=True
以上如果需要在原数据上直接做更改,需设置参数inplace=True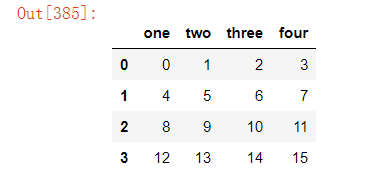 1).删除指定列
1).删除指定列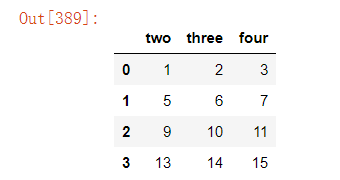 另外,也可通过del df["one"]来实现删除指定列,但该方法不推荐,因为这默认直接在源数据上做更改。
另外,也可通过del df["one"]来实现删除指定列,但该方法不推荐,因为这默认直接在源数据上做更改。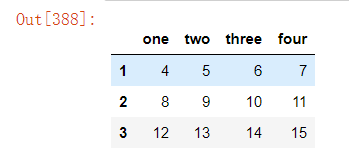 以上如果需要在原数据上直接做更改,需设置参数inplace=True
以上如果需要在原数据上直接做更改,需设置参数inplace=True【本文地址】
今日新闻 |
推荐新闻 |